EPTIC
European Parliament Translation and Interpreting Corpus
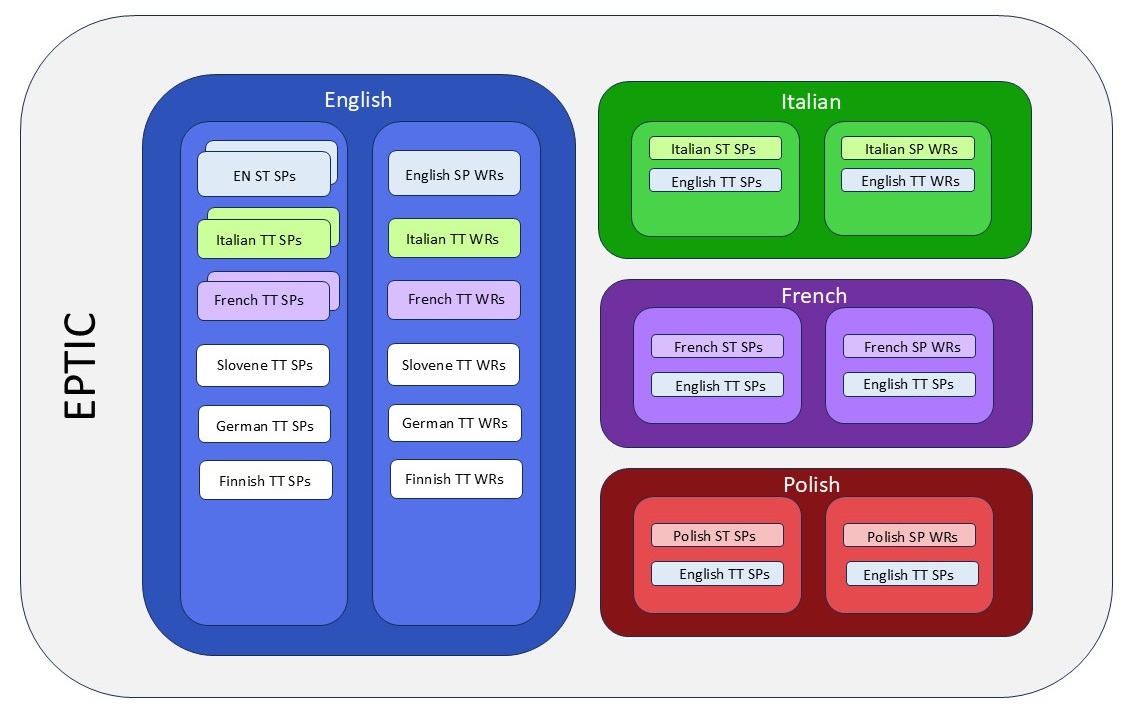
The European Parliament Translation and Interpreting Corpus (EPTIC) is an intermodal parallel corpus comprised of speeches delivered at the European Parliament, as well as their official interpretations and translations. The corpus has been compiled based on data collected from the official website of the European Parliament, where verbatim reports and videos of the speeches with multilingual audio tracks are made publicly available (until 2011 together with the official translations). Sub-corpora are aligned to each other at sentence level, and transcripts of speeches and interpretations are time-aligned with the corresponding videos.
Due to its unique structure, EPTIC allows its users to compare:
- interpretations and translations (in various languages)
- interpreted or translated language with non-interpreted or non-translated language
- native English with non-native English
- orthographic transcripts with video recordings
EPTIC is a collaborative effort of a team of researchers led by the University of Bologna. At present EPTIC includes texts in English, French, Italian, German, Finnish, Polish and Slovenian. The corpus can be accessed via NoSketch Engine (Rychlý 2007), which is an open source corpus management system allowing multiple alignments.
For more information on the corpus, see the documentation section.
License
We assume that textual data available through this platform are treated under the fair use doctrine.